
In this post, I am actually writing all queries that we use day to day as a cheat sheet.
Are you thinking of trying Elastic Search for a long time and didn’t get a chance or proper infrastructure. Then you can try creating Elastic search in Docker Playground and play with it.
Login to https://labs.play-with-docker.com/ and create an instance and excute following single cluster commands.
If you have Docker installed on your developer machine well just ignore Docker Playground
docker network create somenetwork
docker run -d --name elasticsearch --net somenetwork -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.8.0
docker run -d --name kibana --net somenetwork -p 5601:5601 kibana:7.8.0
If you want to try multi-cluster setup visit my another blog post How to deploy an Elastic Search cluster consisting of multiple hosts using ES docker image?
Cluster and node status
An Elastic search cluster is a combination of multiple nodes (Can be physical Machines or VM’s or multiple docker containers on the same host or multiple docker containers on different hosts).
Usually, In the Production environment, we will have a cluster with more than 1 shard. But usually, in Dev environment we can go with a cluster with 1 Node.
Index is a collection of documents of the same type and Shard is a Lucene index that contains documents of a specific index.
Replica Shard is a copy of Primary Shard. The main reason for having a replica shard is to make sure that even if the primary shard /node is down, but still we want our application to run.
Now let’s see when we need to go with Multinode cluster or single node cluster and also when we should do sharding.
Example 1: We are expecting to store documents related to a Q&A site. I am expecting that the overall load of my site will never exceed 50GB. My machine size is around 1TB and I gave a good amount of RAM. I am not worried even If my site is down for a certain time(even hrs) and I can restore data from somewhere or ok to loose data during downtime or ok even if the data is completely lost because of a hardware failure. — 1Node 1shard 0Replica Shards
That is because, our index data will easily fit in this machine. Even if my node is down I am sure it will not impact my business and I can run some tools or scripts to copy data from other DB’s like RDBMS(Only if we have the data stored in RDBMS) or If we dont have this data at other places, even then I am ok to loose complete data.
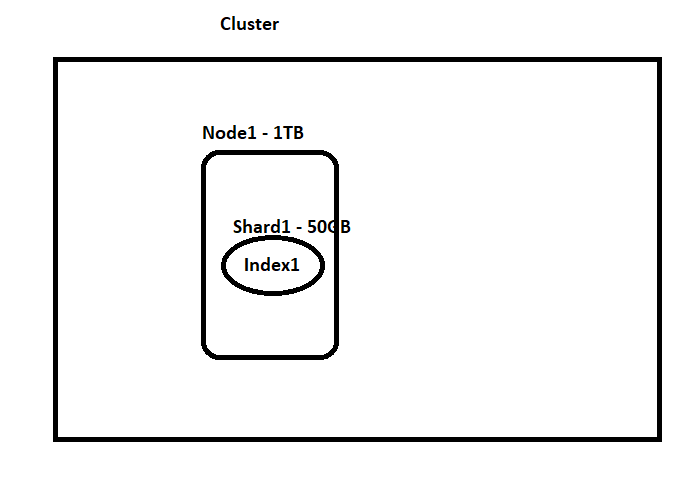
Example 2: We are expecting to store documents related to a Q&A site. I am expecting that the overall load of my site will never exceed 50GB. My machine size is around 1TB and I gave a good amount of RAM. I am not worried even If my site is down for a certain time(even hrs) and I can restore data from the snapshot and It is ok to lose data during downtime but not complete data. — 1Node 1shard 0Replica Shards
That is because our index data will easily fit in this machine. Even if my node is down I am sure it will not impact my business and I can run some tools or scripts to copy data from other DB’s like RDBMS(Only if we have the data stored in RDBMS) and also I can get to the previous state using a snapshot and it is ok to lose the latest data that is not present in the snapshot.
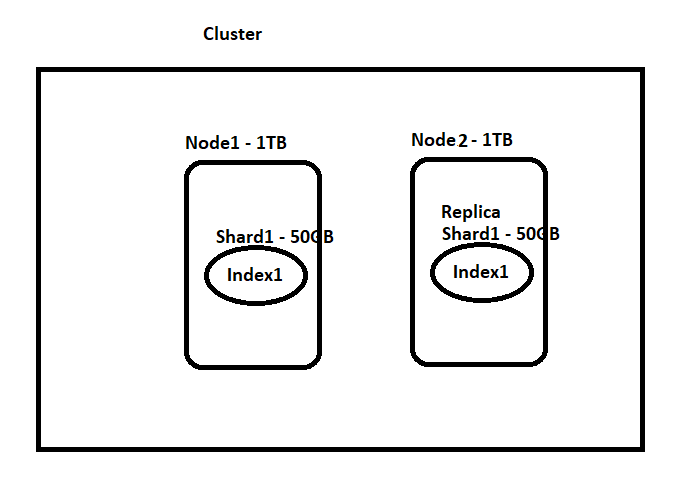
Example 3: We are expecting to store documents related to a Q&A site. I am expecting that the overall load of my site will never exceed 50GB. My machine size is around 1TB and I gave a good amount of RAM. I want to make sure that we will not have any downtime but I am ok to take the minimal chance of downtime. — 2Node 1shard 1 or more Replica Shards
In this case, I am sure that all my data will fit into my single node but I need to have another node(or multiple nodes based on the number of replica shards we want). This is because In order to have replication(copy of primary shard) to minimize downtime we need another node. Ideally, we cannot have Primary shard and replication shards on the same node and that will not solve the purpose of replication because let’s assume the node is down, then both primary and replica shards will be down and there is no point in replication. But if we distribute primary and replica shards between 2 nodes, then even though 1st node with primary shard is down, we can still serve results from replica shard present in 2nd node. But in unfortunate conditions where both the nodes go down then no one can save us :(
Example 4: We are expecting to store documents related to a Q&A site. I am expecting that the overall load of my site might be around 1.5TB. My machine size is around 1TB and I gave a good amount of RAM. I want to make sure that we will not have any downtime but I am ok to take the minimal chance of downtime. — Now read below section and decide :)
In this case, I am sure that my data will not fit into a single machine, so I need to divide data.
Let’s say I want to go with 2 shards(750GB each) and 2 nodes. So I’ll have S1, S2(each 750GB) and I also want to have replication and I want to have 1 replica for each shard. So this will add another 2 shards(replica shards) each with 750GB. So in total we will have 4 shards(S1, S2, P1, P2) and total size is 750*4=3TB but I have only 2TB and this will not work out.
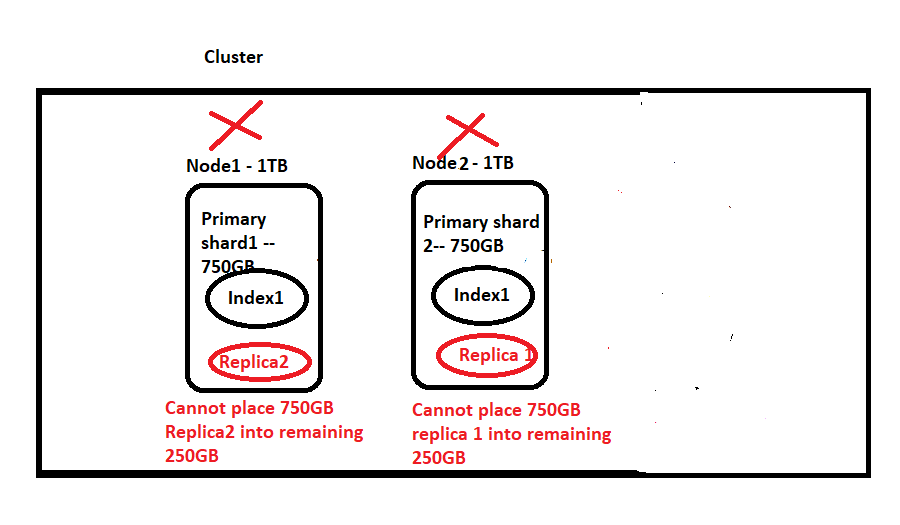
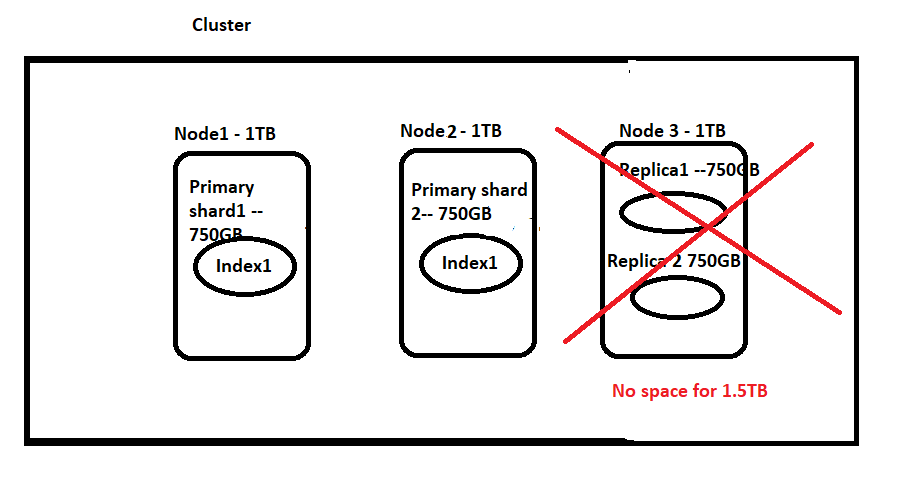
Now let’s say we want to go with 3Nodes and 2 shards. So I’ll have S1, S2(each 750GB) and I also want to have replication and I want to have 1 replica for each shard. So this will add another 2 shards(replica shards) each with 750GB. So in total, we will have 4 shards(S1, S2, P1, P2) and the total size is 750*4=3TB, and I have 3 nodes each with 1TB. So is this going to work out? Let’s see, Node1 will take Shard1(Shard1 will occupy 750GB out of 1TB, so we cannot accommodate any replica or primary shard here.). Next, Shard2 gets allocated on Node2(so this will occupy 750GB and 250GB free space left unused and I cannot accommodate Replica1 or 2). Now we are left with Node3 (with 1TB). But here I cannot accommodate my 2 replicas(750GB+750GB != 1TB). SO THIS WILL FAIL.
Now let’s say we want to go with 4Nodes and 2 shards. So I’ll have S1, S2(each 750GB) and I also want to have replication and I want to have 1 replica for each shard. So this will add another 2 shards(replica shards) each with 750GB. So in total, we will have 4 shards(S1, S2, P1, P2) and the total size is 750*4=3TB, and I have 4 nodes each with 1TB. So is this going to work out? Let’s see Node1 will take Shard1(Shard1 will occupy 750GB out of 1TB, so we cannot accommodate any replica or primary shard here.). Next, Shard2 gets allocated on Node2(so this will occupy 750GB and 250GB free space left unused and I cannot accommodate Replica1 or 2). Now we are left with Node3 and Node4(with 1TB each). So I can add these 2 replicas on to these 2 nodes(Node3 and Node4).
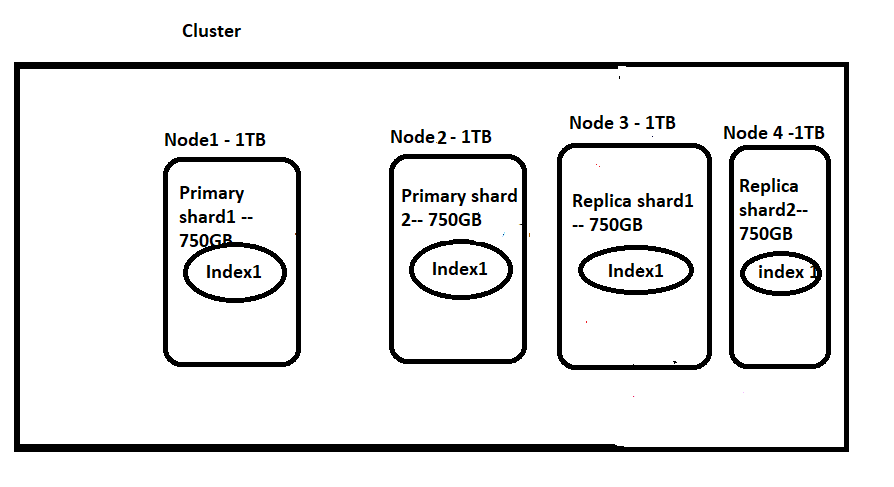
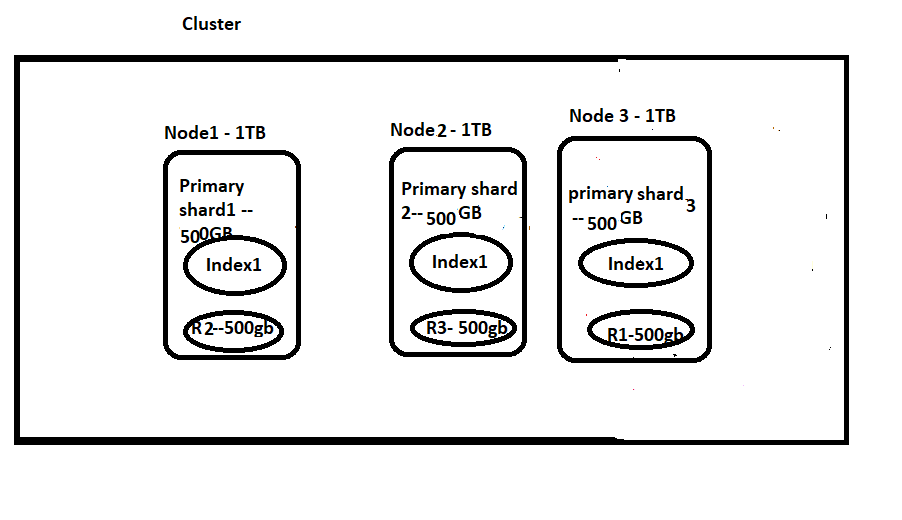
But No I want to go with only 3 Nodes. Can I somehow accommodate my data?
Let me try to reduce the shard size to 500GB. So to accommodate 1.5TB, I need to have 3 primary shards(p1,p2,p3), and also as I want to have replication, I need to have another 3 replicas for each primary shard(R1, R2, R3). So let’s assume that Node1 takes P1+R2(1TB)(We cannot have Primary and Replica shard on the same node because, If that node is down we will lose all data). Now, Node2 will take P2+R3(1TB) and Node3 will take P3+R1(1TB). So this way by increasing the number of shards, I am able to adjust all data in 3 nodes.
Let’s say my Node1 is down, So I can still fetch data Shard1 data from R1 present in Node3 and the downtime is zero.
These are the commands to get information related to clusters and nodes.
GET /_cluster/health?pretty
GET /_cluster/health?wait_for_status=yellow&timeout=50s
GET /_cluster/state
GET /_cluster/stats?human&pretty
GET /_cluster/pending_tasks
GET /_nodes
GET /_nodes/stats
GET /_nodes/nodeId1,nodeId2/stats
Thanks,
Pavan Kumar Aryasomayajulu