
Hi, In this post we will see how to get started with Apache Kafka C#. In this article I’ll be using Kafka as Message Broker. So basically I’ll have 2 different systems. One is Producer and the Other is Consumer. Basically a producer pushes message to Kafka Queue as a topic and it is consumed by my consumer.
Here I’ll basically focus on Installation and a sample C# console applications. One acts as a consumer and the other as a Producer.
Installing Kafka on Windows:
Download from this url http://kafka.apache.org/downloads
Now download Kafka from this http url

After downloading the file, unzip into a location on your machine. Now navigate to ** your_location\kafka_2.11-2.1.1\bin\windows**
/bin directory represents all the binary files which are helpful to start Kafka server different operating systems. As we are working with the windows machine, there will be a folder named windows under /bin directory, which has all the windows related stuff.
/config directory contains all configuration details about Kafka server, zookeeper, and logs. All configurations have their default values if you wanted to change any config details like port you can freely go an change accordingly.
Start the Zookeeper:
We can start the server with default configuration
Use the command “zookeeper-server-start.bat ../../config/zookeeper.properties”
C:\Pavan\Softwares\kafka_2.11-2.1.1\bin\windows>zookeeper-server-start.bat ../../config/zookeeper.properties
[2019-02-26 15:03:16,587] INFO Reading configuration from: ..\..\config\zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2019-02-26 15:03:16,592] INFO autopurge.snapRetainCount set to 3 (org.apache.zookeeper.server.DatadirCleanupManager)
[2019-02-26 15:03:16,593] INFO autopurge.purgeInterval set to 0 (org.apache.zookeeper.server.DatadirCleanupManager)
[2019-02-26 15:03:16,593] INFO Purge task is not scheduled. (org.apache.zookeeper.server.DatadirCleanupManager)
[2019-02-26 15:03:16,594] WARN Either no config or no quorum defined in config, running in standalone mode (org.apache.zookeeper.server.quorum.QuorumPeerMain)
[2019-02-26 15:03:16,617] INFO Reading configuration from: ..\..\config\zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
Start Apache Kafka:
Use the command “kafka-server-start.bat ../../config/server.properties”
C:\Pavan\Softwares\kafka_2.11-2.1.1\bin\windows>kafka-server-start.bat ../../config/server.properties
[2019-02-26 15:08:42,212] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
[2019-02-26 15:08:42,694] INFO starting (kafka.server.KafkaServer)
[2019-02-26 15:08:42,695] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer)
[2019-02-26 15:08:42,720] INFO [ZooKeeperClient] Initializing a new session to localhost:2181. (kafka.zookeeper.ZooKeeperClient)
Now we can see that both Zookeeper and Kafka servers are running successfully.
Understanding Basics Of Kafka:
Before actually going into programming. First of all let us try to understand some of the basic terminologies involved in Kafka.
As per the official site
Apache Kafka® is a distributed streaming platform. What exactly does that mean? A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Lets try to decode above statements.
Process_A(Publisher) sends data( can be multiple messages) under a common name which can be called as topic name. Now Process_B(Consumer) subscribes to the same topic and whenever there is a message or record sent by Process_A (Publisher), it is recieved and processed by Process_B(Consumer).
In this case there are chances of Process_B(consumer) down. So Process_A sends a message but Process_B is down.
What is going to happen in this case?
Are we going to loose the message sent by Process_A?
No, we are not going to loose the message, Kafka takes care of this and it stores this message internally untill the message is consumed by the consumer.
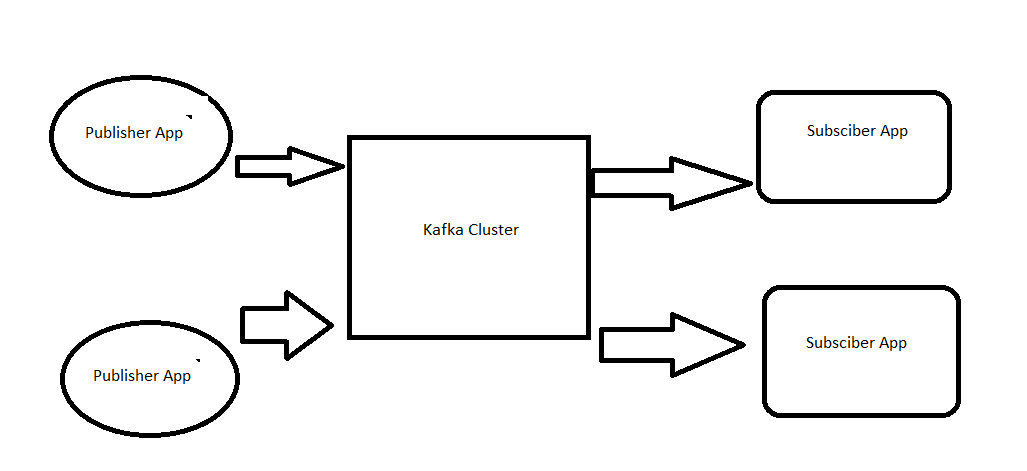
Publisher:
Publishers are applications which send messages to a Topic. For example, I have a topic called “ResumeProcessor” and an application which extracts raw resumes by scrapping. So my application it scrapes resumes from internet and then it posts that data to my “ResumeProcessor” topic.
Topic:
A topic is like a place where a publisher writes all message and a consumer picks from it. In my above example “ ResumeProcessor” is my topic to which different scrapped resumes content is written and from there subscribers pick.
Structure of a Topic:
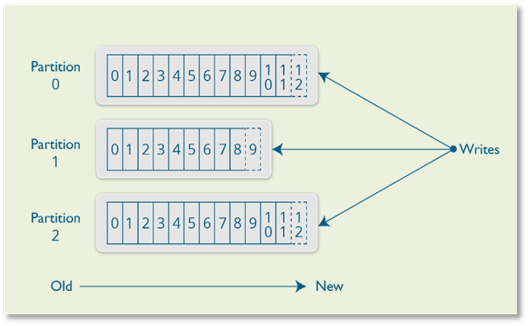
- Each topic is divided into configured number of partitions. By default it is based on the number of consumers ina group.
- Whenever a new message is sent, it is appended to the partition and it is immutable.
- Data in a topic is persisted for a configurable amount of time ( in .properties file). For example if the retension period is set to 1 day, then the record will be stored for the next one day.
Consumers:
Consumers are applications which listen to a topic and when ever a publisher sends a message, it is picked up by the consumer.
C# code for consumer and Producers:
Now as we have kafka environment ready, lets try to publish some data and consume it using C# clients for Kafka.
There are many clients available in the market( Nuget Packages) lets see which one to use.
By querying Nuget site as following https://www.nuget.org/packages?q=kafka&prerel=false I see that there are many packages available.
But among those, I see 2 predominent ones and I am planning to use “Confluent.Kafka” as this seems to be promising and microsft acknowledged it.
https://www.nuget.org/packages/Confluent.Kafka/0.11.6
Note: When Installing this package, make sure that we have include pre-release selected. Because of the classes which I am using in my example are present in the pre-release version or else you’ll be see a message ** “There is no ProducerConfig in Confluent.Kafka dll”**
Producer sample:
using System;
using System.Threading.Tasks;
using Confluent.Kafka;
namespace Kafka_Producer
{
class Program
{
public static async Task Main(string[] args)
{
var config = new ProducerConfig { BootstrapServers = "localhost:9092" };
using (var p = new ProducerBuilder<Null, string>(config).Build())
{
try
{
var dr = await p.ProduceAsync("resume-processor", new Message<Null, string> { Value = DateTime.Now.ToShortDateString() });
Console.WriteLine($"Delivered '{dr.Value}' to '{dr.TopicPartitionOffset}'");
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"Delivery failed: {e.Error.Reason}");
}
}
Console.ReadLine();
}
}
}
- Initially we are initializing a config which specifies details of the Kafka server
- Then we are actually building the Producer by passing above config data
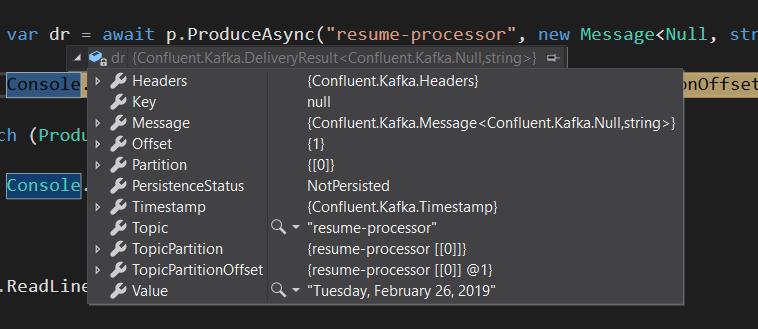
- Now we are actually trying to produce a message to the topic “resume-processor” with a message
- Once the message is written to the topic, we are getting details(DeliveryResults) related to message , this will have information related to the partition and the offset where the record is stored.
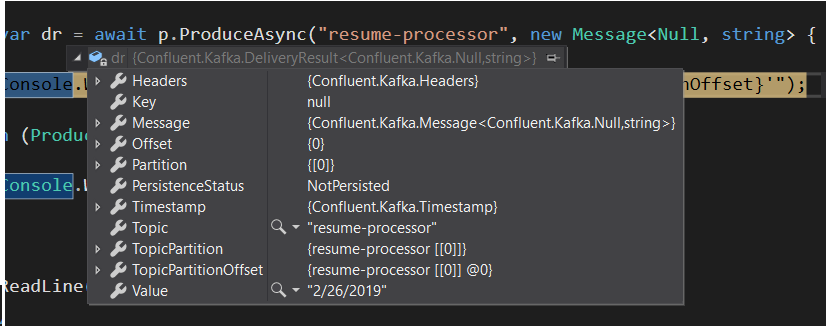
Here we can see that the message is stored in the topic “resume-processor” and we have only 1 partition ( with index 0) and the message is stored in the offset 0.
Now when I tried to run the same application again with a different message, we can see that it is stored in the same partition 0 but in a different offset.
Subscriber sample:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
using Confluent.Kafka;
namespace ConsoleApp6
{
class Program
{
public static void Main(string[] args)
{
var conf = new ConsumerConfig
{
GroupId = "test-consumer-group",
BootstrapServers = "localhost:9092"
};
using (var c = new ConsumerBuilder<Ignore, string>(conf).Build())
{
c.Subscribe("resume-processor");
try
{
while (true)
{
try
{
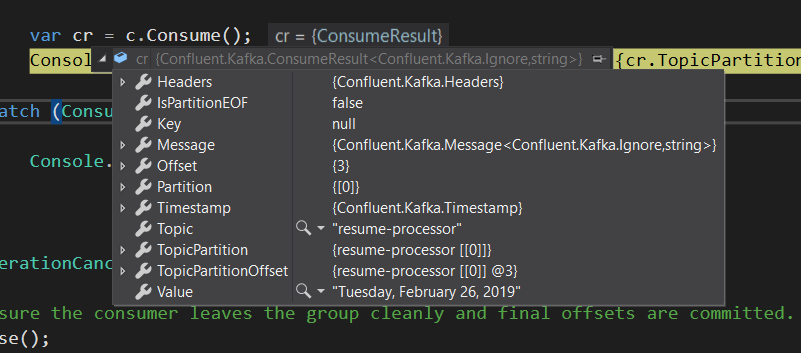
var cr = c.Consume();
Console.WriteLine($"Consumed message '{cr.Value}' at: '{cr.TopicPartitionOffset}'.");
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occured: {e.Error.Reason}");
}
}
}
catch (OperationCanceledException)
{
// Ensure the consumer leaves the group cleanly and final offsets are committed.
c.Close();
}
}
}
}
}
- Initially we are creating a config object with server and consumer group name
- Now we are actually creating a consumer and then subscribe to the same topic to which messages were sent in the Producer application
- Finally we are consuming data when ever we have some data in topic.
Keywords: kafka c#, apache kafka, kafka producer, kafka consumer, kafka server
Thanks,
Pavan